
论文简述
PAI-Diffusion中文开源文图生成模型系列及云上推理服务
在过去几年中,Stable Diffusion类文图生成模型在AIGC领域崭露头角。阿里云人工智能PAI团队参考了Stable Diffusion的模型结构,结合中文语言的特点,通过对中文预训练数据的处理和过滤,以及训练过程的优化,提出了PAI-Diffusion系列中文文图生成模型,实现了图像生成质量的大幅提升和风格多样化。在这一工作中,PAI-Diffusion系列一共12个中文模型(包括基础模型、LoRA、ControlNet等)全部开源,与开发者一起共同推动AI生成内容技术的发展,创造出更有创意和影响力的作品。这一工作还包括了两个PAI-Diffusion模型的推理工具。其中,Chinese SD WebUI是Stable Diffusion WebUI的插件,用于零代码的方式生成用户所需的图像;Diffusers-API通过API调用的方式,支持支持中文模型的在线部署。详细工作介绍参见论文和技术博客。上述工作也将在ACL 2024会议上进行展示。

面向Stable Station的交互式多轮prompt生成模型DiffChat
基于扩散模型的文图生成模型(例如Stable Diffusion)的效果有时会受到输入文本即提示词撰写的影响。当用户对创作的图像有特定需求或者希望执行特定的内容修改时,通常需要进行反复多次的提示词修改,且每次尝试的结果都是不可预期的。 这造成了不可忽略的时间和计算资源的耗费。基于这一问题,我们提出了DiffChat,这是一个文到文的多轮生成模型,可以根据用户的需求指令对原始提示词进行适当的修改,得到新的提示词来使得文到图生成模型能够生成更美观且符合指令的图像。整个过程做到了用户和文图生成模型的迭代交互,最终完成用户的创作需求。
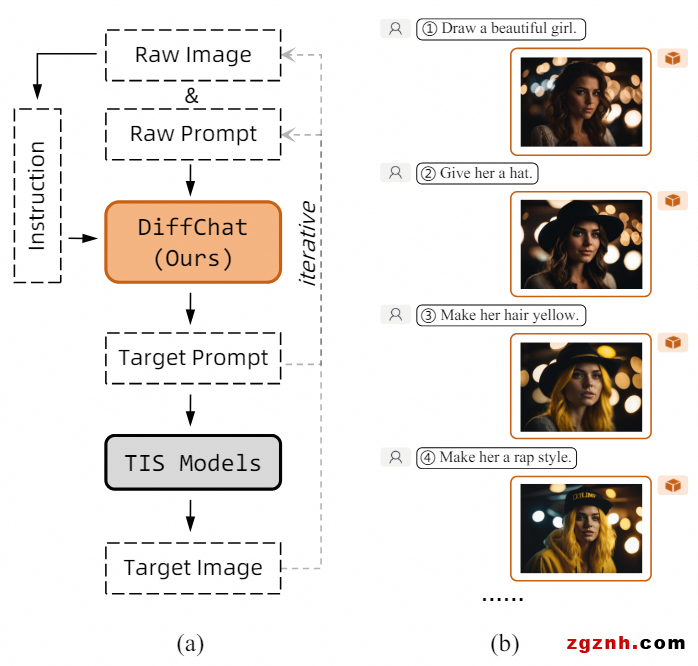
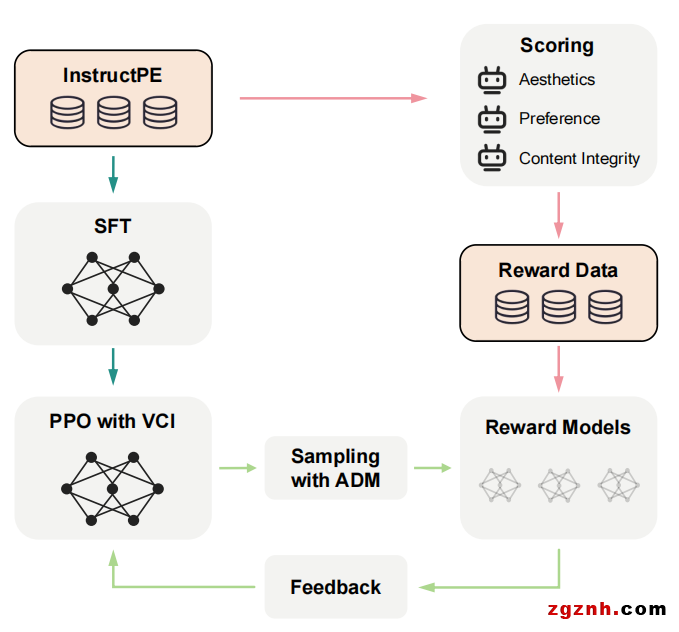
该方法首先通过提示词美化和提示词工程的方法建立了一个和该任务高度相关的数据集。 然后,在执行有监督微调训练后,为了进一步提升模型性能,该方法提出了一种带有美学、人类偏好和内容完整度反馈的强化学习技术来进一步优化模型。同时,该方法还提出了动作空间动态修正和基于内容完整度的状态价值估计两项技术进行额外改进。实验结果表明,该方法显著优于一些具有竞争力的同类方法。
长尾知识对检索增强大语言模型的作用
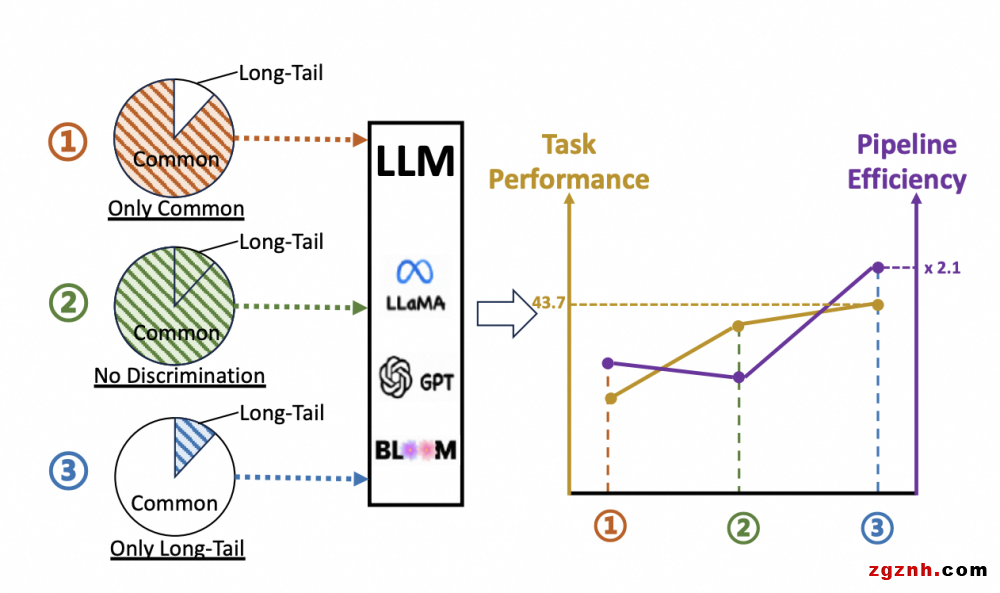
检索增强生成(retrieval-augmented generation,RAG)通过检索与用户查询相关的文档,在提升大型语言模型(large language models,LLM)的知识能力方面表现出优异的性能。然而,RAG只关注通过不加区分地使用检索到的信息增强查询来提高LLM的响应质量,很少关注LLM真正需要什么类型的知识来更准确地回答原始查询。在本文中,我们认为长尾知识对RAG是至关重要的,因为LLM在大规模的预训练的时候已经记住了通用高频的世界知识。在此基础上,提出了一种简单有效的长尾知识检测方法。具体地说,本文提出了一种新的基于统计和语义的生成性期望校准误差(GECE)度量方法来度量知识的“长尾性”。因此,只有当输入查询涉及长尾知识时,我们才检索相关文档并将其注入到大模型中。实验结果表明,与现有的RAG方法相比,该方法在平均推理时间上实现了4倍以上的加速,在下游任务上性能得到了一致的提高。
具体来说,pred和ref分别表示生成的文本和模型任务的标准结果。M(pred, ref)是模型对应的METEOR score度量结果。平均token概率中的P(ti)表示由LLM产生的第i个token的概率,n是token序列长度。对于分母部分,α是平均词频。我们可以看到,长尾实例的α值较小,因此其倒数将较大。另外,▽ins是当前实例的梯度,E(▽ins)是整个数据集的平均梯度。为了获得梯度,我们仅通过使用数据集微调LLM来运行前向和后向梯度传递。我们可以看到,与数据集的平均得分相比,长尾实例具有更小的梯度▽ins,从而获得更小的点积E(▽ins)·▽ins。
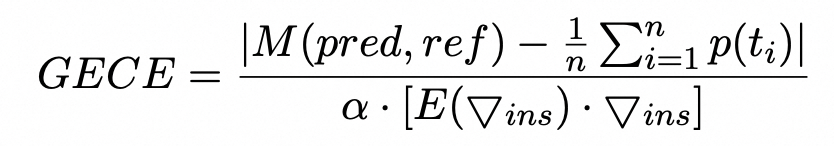
面向大语言模型的知识编辑算法DAFNet
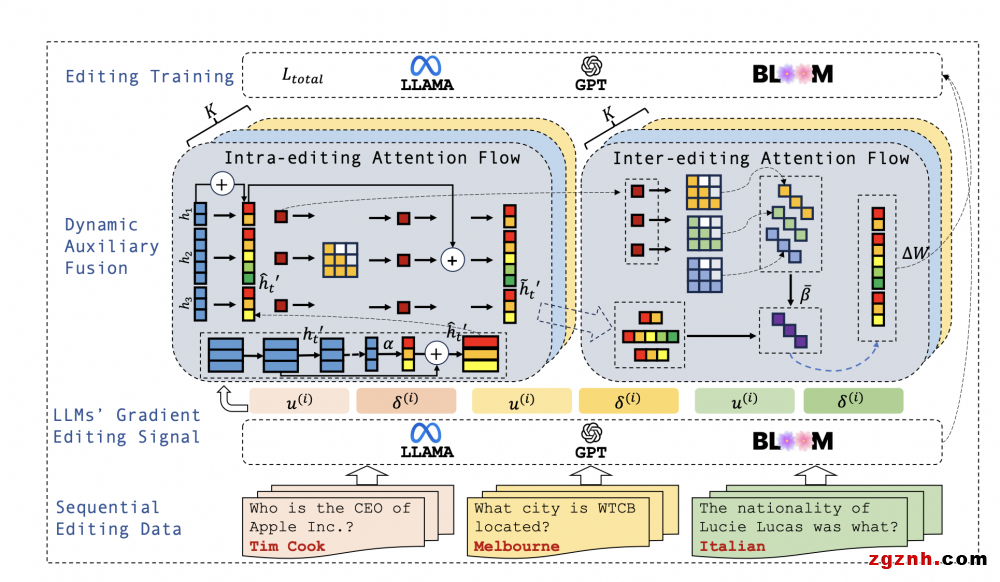
近年来,大型语言模型(LLM)虽然取得了令人印象深刻的研究成果,但仍存在幻觉现象,即产生虚假信息。模型编辑是修复LLMs中事实错误的任务;然而,以往的工作大多将其视为一次性编辑任务,很少关注LLM产生的不断出现的错误。我们解决了顺序模型编辑(SME)的任务,旨在不断纠正错误。设计了一种动态辅助融合网络(DAFNet),以增强整个序列中事实知识之间的语义交互,防止多知识三元组编辑过程中的灾难性遗忘。
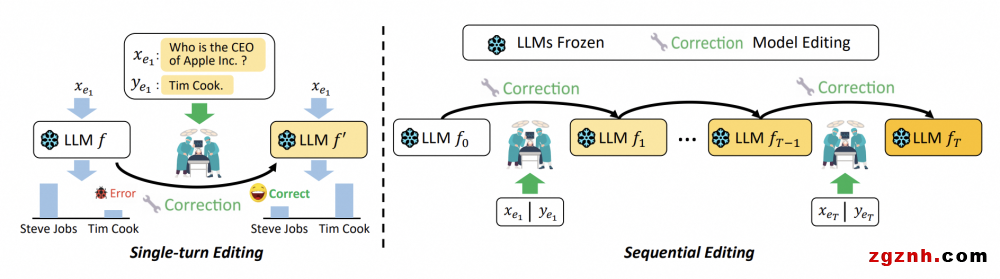
具体来说,(1) 对于关系三元组内的语义融合,我们在LLMs中将编辑内的注意流聚合为具有标记级粒度的自回归自注意力。我们进一步利用多层对角互编辑注意力流更新整个序列级粒度的加权表示。(2) 考虑到序列编辑需要辅助参数来存储知识,我们构造了一个新的数据集DAFSet,实现了最近性、流行性、长尾性和鲁棒性,增强了序列编辑的通用性。实验结果表明,DAFNet在单轮编辑和顺序编辑中均显著优于强基线。DAFSet的使用还不断提高了其他基于辅助网络的方法在各种场景中的性能。
产品化服务
上述科研成果也在人工智能平台PAI的各个模块进行了深度的集成和整合,持续为PAI客户提供AI模型训练和推理相关服务。其中,Chinese SD WebUI作为Stable Diffusion WebUI的插件与PAI-EAS无缝兼容,支持5分钟内一键在PAI-EAS拉起中文AIGC应用。Diffusers-API与PAI-EAS进行融合,使客户更加容易在云上部署各类文图生成大模型,用于生产环境的实时调用。此外,PAI-QuickStart集成了超过50个热门大语言模型,及其多种训练和推理方式,使客户更加简单地微调和部署大语言模型。在未来,我们也将在PAI平台上持续提供业界领先的算法和模型能力给广大客户。
论文汇总
论文名字:PAI-Diffusion: Constructing and Serving a Family of Open Chinese Diffusion Models for Text-to-image Synthesis on the Cloud
论文作者:汪诚愚、段忠杰、刘冰雁、邹心怡、陈岑、贾奎、黄俊
论文pdf链接:https://arxiv.org/abs/2309.05534
论文名字:DiffChat: Learning to Chat with Text-to-Image Synthesis Models for Interactive Image Creation
论文作者:汪嘉鹏、汪诚愚、曹庭锋、黄俊、金连文
论文pdf链接:https://arxiv.org/abs/2403.04997
论文名字:On the Role of Long-tail Knowledge in Retrieval Augmented Large Language Models
论文作者:李东阳、严俊冰、张涛林、汪诚愚、何晓丰、黄龙涛、薛晖、黄俊
论文pdf链接:https://arxiv.org/pdf/2406.16367
论文名字:DAFNet: Dynamic Auxiliary Fusion for Sequential Model Editing in Large Language Models
论文作者:张涛林、陈颀周、李东阳、汪诚愚、何晓丰、黄龙涛、薛晖、黄俊
论文pdf链接:https://arxiv.org/abs/2405.20588
阿里云人工智能平台PAI长期招聘研究实习生。团队专注于深度学习算法研究与应用,重点聚焦大语言模型和多模态AIGC大模型的应用算法研究和应用。
 粤公网安备 44030702001206号
粤公网安备 44030702001206号