
引言
Mixtral 8x7B 是Mixtral AI最新发布的大语言模型,在许多基准测试上表现优于 GPT-3.5,是当前最为先进的开源大语言模型之一。阿里云人工智能平台PAI是面向开发者和企业的机器学习/深度学习平台,提供了对于 Mixtral 8x7B 模型的全面支持,开发者和企业用户可以基于 PAI-快速开始(PAI-QuickStart)轻松完成Mixtral 8x7B 模型的微调和部署。
Mixtral 8x7B 模型介绍
Mixtral 8x7B 是基于编码器(Decoder-Only)架构的稀疏专家混合网络(Sparse Mixture-Of-Experts,SMoE)开源大语言模型,使用 Apache 2.0 协议发布。它的独特之处在于对于每个 token,路由器网络选择八组专家网络中的两组进行处理,并且将其输出累加组合,因此虽然 Mixtral 8x7B 拥有总共 47B 的参数,但每个 token 实际上只使用13B的活跃参数,推理速度与13B模型相当。
Mixtral 8x7B 支持多种语言,包括法语、德语、西班牙语、意大利语和英语,支持的上下文长度为32K token,并且在所有的评估的基准测试中均达到或优于 Llama-2-70B 和 GPT-3.5,特别是在数学、代码生成和多语言基准测试中,Mixtral 大大优于 Llama-2-70B。
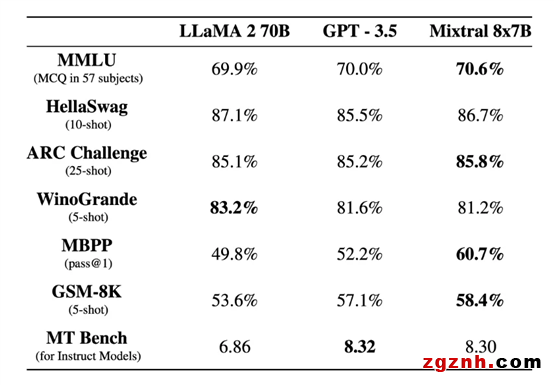
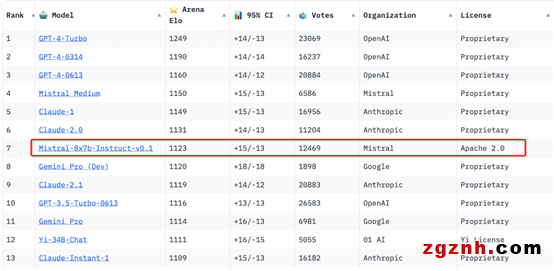
Mixtral AI 同时也发布了 Mixtral 8x7B 指令微调版本 Mixtral-8x7B-Instruct-v0.1,该版本通过监督微调和直接偏好优化(Direct Preference Optimization, DPO)进行了优化,以更好地遵循人类指令,对话能力领先于目前的其他开源模型的指令微调版本。
PAI-QuickStart 介绍
快速开始(PAI-QuickStart)是阿里云人工智能平台PAI的产品组件,它集成了国内外 AI 开源社区中优质的预训练模型,涵盖了包括大语言模型,文本生成图片、语音识别等各个领域。通过 PAI 对于这些模型的适配,用户可以通过零代码和 SDK 的方式实现从训练到部署再到推理的全过程,大大简化了模型的开发流程,为开发者和企业用户带来了更快、更高效、更便捷的 AI 开发和应用体验。
运行环境要求
本示例目前仅支持在阿里云乌兰察布地域,使用灵骏集群环境运行。
资源配置要求:GPU 推荐使用 GU108(80GB显存),推理需要2卡及以上资源,LoRA微调需要4卡及以上资源。
阿里云 PAI 灵骏智算服务资源开通和管理请参考官网文档:灵骏智算资源的购买开通
通过PAI控制台使用模型
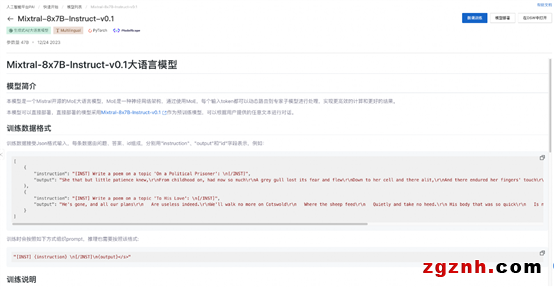
开发者可以在 PAI 控制台的“快速开始”入口,找到 Mixtral-7x8B-Instruct-v0.1 的模型,Mixtral-7x8B-Instruct-v0.1 的模型卡片如下图所示:
模型部署和调用
PAI 提供的 Mixtral-7x8B-instruct-v0.1 预置了模型的部署配置信息,用户仅需提供推理服务的名称以及部署配置使用的资源信息即可将模型部署到PAI-EAS推理服务平台。
当前模型需要使用灵骏资源组进行部署,请确保选择的资源配额(Quota)中至少有 >=2张GU108 GPU卡的计算资源。
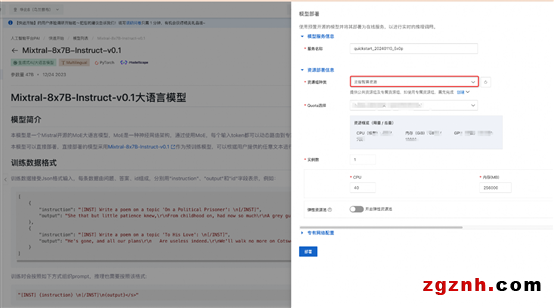
部署的推理服务支持 OpenAI 的 API 风格进行调用,通过推理服务的详情页,用户可以获得服务访问地址(Endpoint)和访问凭证(Token)。使用 cURL 调用推理服务的示例如下:
# 请注意替换为使用服务的Endpoint和Token
export API_ENDPOINT='<ENDPOINT>'
export API_TOKEN='<TOKEN>'
# 查看模型list
curl $API_ENDPOINT/v1/models
-H 'Content-Type: application/json'
-H 'Authorization: Bearer $API_TOKEN'
# 调用通用的文本生成API
curl $API_ENDPOINT/v1/completions
-H 'Content-Type: application/json'
-H 'Authorization: Bearer $API_TOKEN'
-d '{
'model': 'Mixtral-8x7B-Instruct-v0.1',
'prompt': 'San Francisco is a',
'max_tokens': 256,
'temperature': 0
}'
curl $API_ENDPOINT/v1/chat/completions
-H 'Authorization: Bearer $API_TOKEN'
-H 'Content-Type: application/json'
-d '{
'model': 'Mixtral-8x7B-Instruct-v0.1',
'messages': [
{'role': 'user', 'content': '介绍一下上海的历史'}
]
}'
同时也可以通过 OpenAI 的 SDK进行调用,用户首先需要安装 SDK:
# 安装服务调用SDK
python -m pip install openai
通过SDK调用推理服务的示例代码如下:
import openai
# 请使用服务详情页获取的访问地址(ENDPOINT)和访问凭证(TOKEN)替换以下代码的配置。
openai.api_key = '<TOKEN>'
openai.base_url = '<ENDPOINT>' + '/v1'
# 调用对话API
completion = openai.chat.completions.create(
model='Mixtral-8x7B-Instruct-v0.1',
temperature=0.0,
top_p=0.8,
frequency_penalty=0.0,
messages=[{'role': 'user', 'content': '请介绍下你自己。'}],
# stream=True,
)
# 打印输出内容
print(completion.choices[0].message.content)
模型微调训练
PAI 为 Mixtral-8x7B-Instruct-v0.1 模型配置了微调算法,支持用户以开箱即用得方式对 Mixtral-8x7B-Instruct-v0.1 进行微调。
训练算法支持使用 Json 格式输入,每条数据由问题、答案组成,分别用'instruction'、'output'字段表示,例如:
[
{
'instruction': 'Write a poem on a topic 'On a Political Prisoner': ',
'output': 'She that but little patience knew,nFrom childhood on, had now so muchnA grey gull lost its fear and flewnDown to her cell and there alit,nAnd there endured her fingers' touchnAnd from her fingers ate its bit.nDid she in touching that lone wing.'
},
{
'instruction': 'Write a poem on a topic 'To His Love': ',
'output': 'He's gone, and all our plans Are useless indeed.nWe'll walk no more on Cotswold Where the sheep feed Quietly and take no heed. His body that was so quick Is not as younKnew it, on Severn river Under the blue Driving our small boat through.'
}
]
当完成数据的准备,用户可以将数据上传到对象存储 OSS Bucket 中,或是通过指定一个数据集对象,选择在 NAS/CPFS 存储上的数据集。用户也可以使用PAI预置的公共读数据集,直接提交任务测试算法。
算法需要使用 >=4 x GU108(80GB显存)的GPU资源,请确保选择使用的资源配额内有充足的计算资源。
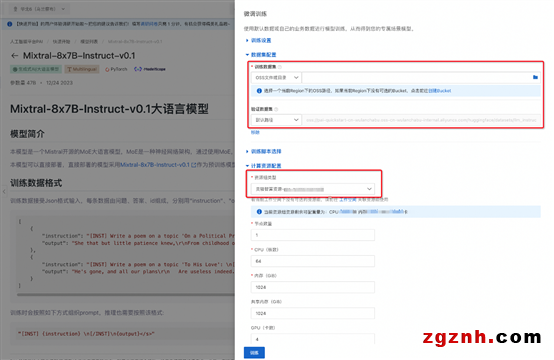
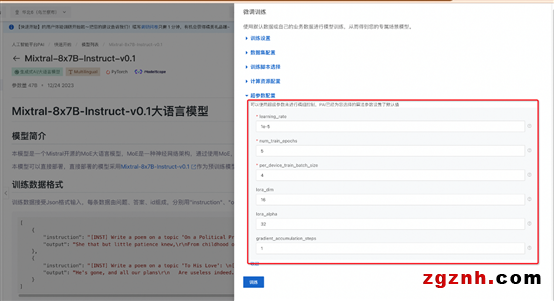
训练算法支持的超参信息如下,用户可以根据使用的数据,计算资源等调整超参,或是使用算法默认配置的超参。

点击“训练”按钮,PAI-QuickStart 开始进行训练,用户可以查看训练任务状态和训练日志。
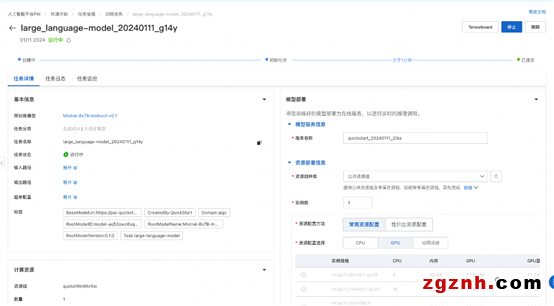
通过页面的 TensorBoard 入口,用户也可以一键打开 TensorBoard 查看模型的收敛情况。
如果需要将模型部署至PAI-EAS,可以在同一页面的模型部署卡面选择资源组,并且点击“部署”按钮实现一键部署。模型调用方式和上文直接部署模型的调用方式相同。
通过PAI Python SDK使用模型
PAI-QuickStart 提供的预训练模型,也支持通过PAI Python SDK进行调用,我们首先需要安装和配置PAI Python SDK,开发者可以在命令行执行以下代码完成。
# 安装PAI Python SDK
python -m pip install alipai --upgrade
# 交互式得配置访问凭证、PAI工作空间等信息
python -m pai.toolkit.config
如何获取 SDK 配置所需的访问凭证(AccessKey),PAI 工作空间等信息请参考文档:如何安装和配置PAI Python SDK。
模型部署和调用
通过 PAI 在模型上预置的推理服务配置,用户仅需提供使用的资源信息,以及服务名称,即可轻松的将 Mixtral 模型部署到 PAI-EAS 推理平台。
from pai.session import get_default_session
from pai.model import RegisteredModel
from pai.common.utils import random_str
from pai.predictor import Predictor
session = get_default_session()
# 获取PAI QuickStart 提供的模型
m = RegisteredModel(
model_name='Mixtral-8x7B-Instruct-v0.1',
model_provider='pai',
)
# 查看模型默认的部署配置
print(m.inference_spec)
# 部署推理服务
# 需提供使用灵骏资源配额ID(QuotaId),要求至少 >= 2张GU108(80G显存)GPU卡的计算资源.
predictor = m.deploy(
service_name='mixtral_8_7b_{}'.format(random_str(6)),
options={
# 资源配额ID
'metadata.quota_id': '<LingJunResourceQuotaId>',
'metadata.quota_type': 'Lingjun',
'metadata.workspace_id': session.workspace_id,
}
)
# 获取推理服务的Endpoint和Token
endpoint = predictor.internet_endpoint
token = predictor.access_token
推理服务的调用请参考以上的 PAI-EAS 部署推理的章节,或是直接使用 PAI Python SDK 进行调用。
from pai.predictor import Predictor
p = Predictor('<MixtralServiceName>')
res = p.raw_predict(
path='/v1/chat/completions',
method='POST',
data={
'model': 'Mixtral-8x7B-Instruct-v0.1',
'messages': [
{'role': 'user', 'content': '介绍一下上海的历史'}
]
}
)
print(res.json())
当测试完成,需要删除服务释放资源,用户可以通过控制台或是SDK完成:
# 删除服务
predictor.delete_service()
模型的微调训练
通过 SDK 获取 PAI QuickStart 提供的预训练模型之后,我们可以查看模型配置的微调算法,包括算法支持的超参配置以及输入输出数据。
from pai.model import RegisteredModel
# 获取PAI QuickStart 提供的 Mixtral-8x7B-Instruct-v0.1 模型
m = RegisteredModel(
model_name='Mixtral-8x7B-Instruct-v0.1',
model_provider='pai',
)
# 获取模型配置的微调算法
est = m.get_estimator()
# 查看算法支持的超参,以及算法输入输出信息
print(est.hyperparameter_definitions)
print(est.input_channel_definitions)
目前,Mixtral-8x7B-Instruct-v0.1 提供的微调算法仅支持灵骏资源,开发者需要通过 PAI 的控制台页面,查看当前的资源配额 ID,设置训练任务使用的资源信息。同时在提交训练作业之前,用户可以根据算法的超参支持,配置合适的训练任务超参。
# 配置训练作业使用的灵骏资源配额ID
est.resource_id = '<LingjunResourceQuotaId>'
# 配置训练作业超参
hps = {
'learning_rate': 1e-5,
'per_device_train_batch_size': 2,
}
est.set_hyperparameters(**hps)
微调算法支持3个输入,分别为:
model:Mixtral-8x7B-Instruct-v0.1 预训练模型
train:微调使用的训练数据集
validation:微调使用的验证数据集
数据集的格式请参考以上章节,用户可以通过 ossutils,控制台操作等方式上传数据到 OSS Bucket,也可以使用 SDK 提供的方法上传到用户配置的Bucket。
from pai.common.oss_utils import upload
# 查看模型微调算法的使用的输入信息
# 获取算法的输入数据,包括模型和供测试的公共读数据集.
training_inputs = m.get_estimator_inputs()
print(training_inputs)
# {
# 'model': 'oss://pai-quickstart-cn-wulanchabu.oss-cn-wulanchabu-internal.aliyuncs.com/huggingface/models/Mixtral-8x7B-Instruct-v0.1/main/',
# 'train': 'oss://pai-quickstart-cn-wulanchabu.oss-cn-wulanchabu-internal.aliyuncs.com/huggingface/datasets/llm_instruct/en_poetry_train_mixtral.json',
# 'validation': 'oss://pai-quickstart-cn-wulanchabu.oss-cn-wulanchabu-internal.aliyuncs.com/huggingface/datasets/llm_instruct/en_poetry_test_mixtral.json',
# }
# 上传用户数据,请注意替换一下的本地文件路径和上传的OSS Bucket路径.
train_data_uri = upload('/path/to/local/train.json', 'path/of/train/data')
validation_data_uri = upload('/path/to/local/validation.json', 'path/of/validation/data')
# 替换使用开发者的训练数据
# training_inputs['train'] = train_data_uri
# training_inputs['validation'] = validation_data_uri
开发者可以参考以上的训练数据格式准备数据,然后将train和validation输入替换为自己的训练和验证数据集,即可轻松得提交模型微调训练作业。通过 SDK 打印的训练作业链接,用户可以在 PAI 的控制台上查看训练任务状态以及日志信息,同时也可以通过 TensorBoard 查看训练作业的进度和模型收敛情况。
from pai.common.oss_utils import download
# 提交训练作业,同时打印训练作业链接
est.fit(
inputs=training_inputs,
wait=False,
)
# 打开TensorBoard查看训练进度
est.tensorboard()
# 等待训练任务结束
est.wait()
# 查看保存在OSS Bucket上的模型路径
print(est.model_data())
# 用户可以通过ossutils,或是SDK提供的便利方法下载相应的模型到本地
download(est.model_data())
用户可以查看文档,了解更多如何通过 SDK 使用 PAI-QuickStart 提供的预训练模型:使用预训练模型 — PAI Python SDK。
结论
Mixtral-8x7B 是当前最为先进的开源大语言模型之一,借助于MoE架构,具有很高的使用性价比,通过 PAI QuickStart 开发者可以轻松地完成Mixtral模型的微调和部署。当然PAI QuickStart 也提供了更多的先进、不同领域的模型,欢迎开发者前来探索使用。
相关资料
Mixtral 8x7B 模型:
https://mistral.ai/news/mixtral-of-experts/
PAI 快速开始:
https://help.aliyun.com/zh/pai/user-guide/quick-start-overview
PAI Python SDK:
https://github.com/aliyun/pai-python-sdk
阿里云PAI灵骏智算服务:
https://www.aliyun.com/product/bigdata/learn/pailingjun
 粤公网安备 44030702001206号
粤公网安备 44030702001206号