近期,阿里云人工智能平台 PAI 团队发表的图像编辑算法论文在 MM2024 上正式亮相发表。ACM MM(ACM国际多媒体会议)是国际多媒体领域的顶级会议,旨在为研究人员、工程师和行业专家提供一个交流平台,以展示在多媒体领域的最新研究成果、技术进展和应用案例。其主题涵盖了图像处理、视频分析、音频处理、社交媒体和多媒体系统等广泛领域。此次入选标志着阿里云人工智能平台 PAI 在图像编辑算法方面的研究获得了学术界的充分认可。
文本到图像合成 (TIS) 已成为计算机视觉与自然语言处理 (NLP) 交叉领域的重要前沿,其能够根据文本描述生成视觉上引人注目的图像。基于文本引导的图像编辑任务使用户能够通过简单的文字描述来指导图像的修改,无需使用复杂的图像编辑软件或具备专业知识即可实现编辑效果。其中 Traing-free 的文本引导图像编辑 (TIE) 已成为一个重要的研究方向,利用预训练的 TIS 模型,直接通过文本提示来编辑图像,用户可以直接输入文本,对图像进行多种编辑操作,包括颜色变化、物体的添加或去除、风格转换等。这种交互式编辑方式显著降低了图像编辑的门槛,使得创意表达变得更加便捷和个性化。
尽管当前的 TIE 算法取得了显著进展,但它们仍存在一些局限性。如图1所示,现有 TIE 方法在编辑多个对象时面临挑战。多对象编辑的复杂性会导致编辑对象丢失(例如,丢失一个苹果)、属性缺失(例如,斑点)和背景保留不完整等问题。

图1. 图像编辑的效果对比以及我们提出方法的结果
在本文中,我们提出了 VICTORIA 编辑算法,它利用语言知识来解决在对象场景编辑中因缺失目标(如对象、属性和背景)而导致的问题。VICTORIA 通过分析输入编辑文本中单词之间的依存关系,并将这种关系反映在注意层的中间表示中,从而修正并生成目标图像。图2展示了 VICTORIA 的整体框架。首先,我们通过控制自注意机制来确保原始图像和编辑后图像之间的空间一致性。其次,VICTORIA 分析输入编辑文本中单词之间的依存关系,并在生成目标编辑图像的过程中主动干预交叉注意力图,从而提升目标编辑区域的生成结果。最后,VICTORIA 通过交叉注意图进行图像部分掩码,有效保留原始图像中无需被编辑的区域。
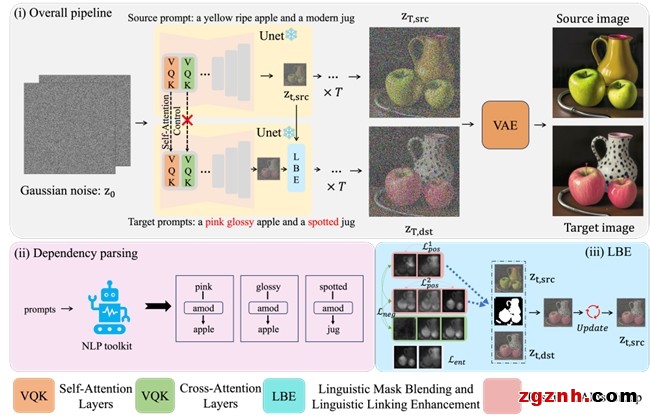
图 2:VICTORIA 在对图像进行编辑的过程示意图
VICTORIA 伪代码如下:

图 3:VICTORIA 在合成图像编辑和真实图像编辑场景下的伪代码
图4展示了 VICTORIA 的编辑结果,它成功地修改了原始图像中多个物体的各种属性、风格、场景和类别。
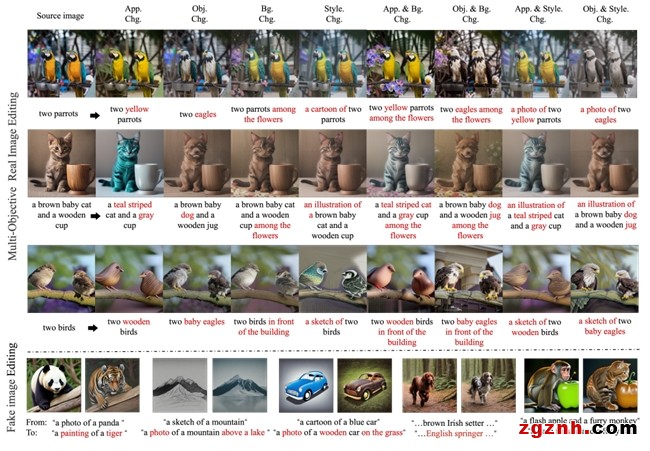
图 4:VICTORIA编辑结果示例
图5对比展示了 VICTORIA 与其他一些 SOTA 图像编辑技术的效果。无论是对真实照片还是合成图像,VICTORIA 均展现出了高效的编辑能力。在所有的案例中,VICTORIA 都能够实现与描述提示高度一致的精细编辑,同时最大限度地保留了原图的结构细节。

图 5:VICTORIA与其他编辑方法的对比
为了更好地服务开源社区,这一算法的源代码已经贡献在自然语言处理算法框架 EasyNLP 中,欢迎各界从业人员和研究者使用。
阿里云人工智能平台 PAI 长期招聘正式员工/实习生。团队专注于深度学习算法研究与应用,重点聚焦大语言模型和多模态 AIGC 大模型的应用算法研究和应用。简历投递和咨询:chengyu.wcy@alibaba-inc.com。
论文信息
论文名字:Attentive Linguistic Tracking in Diffusion Models for Training-free Text-guided Image Editing
论文作者:刘冰雁、汪诚愚、黄俊、贾奎
论文pdf链接:https://openreview.net/pdf?id=efTur2naAS